Friedrich Schleiermacher riet in seinem einflussreichen Werk Hermeneutik und Kritik dazu, einen zu untersuchenden Textabschnitt möglichst im Kontext des ganzen Werkes, der Sprache und des Lebens des Verfassers, und letztlich im Kontext von „Sprachschatz“ und Geschichte des Zeitalters zu betrachten . Durch die massenhafte Digitalisierung von Quellen und den Einsatz digital gestützter Analyseverfahren scheint dieses Ideal heute greifbarer denn je. Der vorliegende Beitrag stellt mit dem 5036 historische Schulbücher umfassenden Korpus „GEI-Digital-2020“ des Leibniz-Instituts für Bildungsmedien | Georg-Eckert-Institut (GEI) eine für die Bildungsgeschichte relevante digitale Ressource vor und demonstriert, wie sich diese Texte in der Korpusmanagement-Umgebung D* mit den darin verfügbaren Werkzeugen webbasiert durch- und untersuchen lassen. Als interaktiv nachvollziehbare Beispiele dienen dabei Recherchen zum Begriff „Leistung“ in den Schulbüchern.
Das Korpus – Entstehung und Besonderheiten
Wie der Name schon andeutet, wurde das „GEI-Digital-2020“ Korpus im Jahr 2020 aus den damals im Projekt „GEI-Digital“ im Volltext verfügbaren Werken erstellt. In GEI-Digital werden laufend historische Schulbuchbestände mit automatisch generierten Volltexten und umfangreichen schulbuchspezifischen Metadaten etwa zu Schulform und Bildungsstufe erschlossen, wobei letztere bislang hauptsächlich über den Bibliothekskatalog (https://opac.lbs-braunschweig.gbv.de/) und im auf Bildungsmedien spezialisierten International TextbookCat für entsprechende Filterungen nutzbar sind. Die Weboberfläche von GEI-Digital selber erlaubt vor allem das Filtern nach Untersammlungen und verschiedene Facetten- und Freitextsuchen (https://gei-digital.gei.de/viewer/index/).
Das Projekt „DiaCollo für GEI-Digital“ wurde durch den hausinternen Seed Fonds „GEI-Innovation 2020“ gefördert. Durch die Zusammenarbeit mit dem Zentrum Sprache an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) konnten mittels verschiedener Natural Language Processing Verfahren weitere Metadaten zu den Bestandteilen der Volltexte generiert und für die Analyse mit den an der BBAW entwickelten und eingesetzten korpuslinguistischen Werkzeugen verfügbar gemacht werden. Auf der Projektwebseite (https://diacollo.gei.de/) stehen neben den Sucheinstiegen auch ein bebildertes Tutorial und Visualisierungen der Metadaten (https://diacollo.gei.de/gei-digital-2020/visualized/) des Korpus zur Verfügung.
Das „GEI-Digital-2020“ Korpus entspricht allerdings in mehrfacher Hinsicht nicht den idealen Standards für Textsammlungen, die üblicherweise mit diesen Werkzeugen untersucht werden: Die Datengrundlage einzelner Zeitabschnitte ist unterschiedlich groß; die Volltexte – und in Konsequenz die mittels Natural Language Processing generierten Zusatzinformationen – sind aufgrund der rein automatisch durchgeführten Texterkennung nicht frei von Fehlern; und einige Texte kommen mehrfach im Korpus vor, etwa in Regionalausgaben oder späteren Auflagen. Dies ist bei der Interpretation von Analyseergebnissen zu berücksichtigen.
Die Werkzeuge
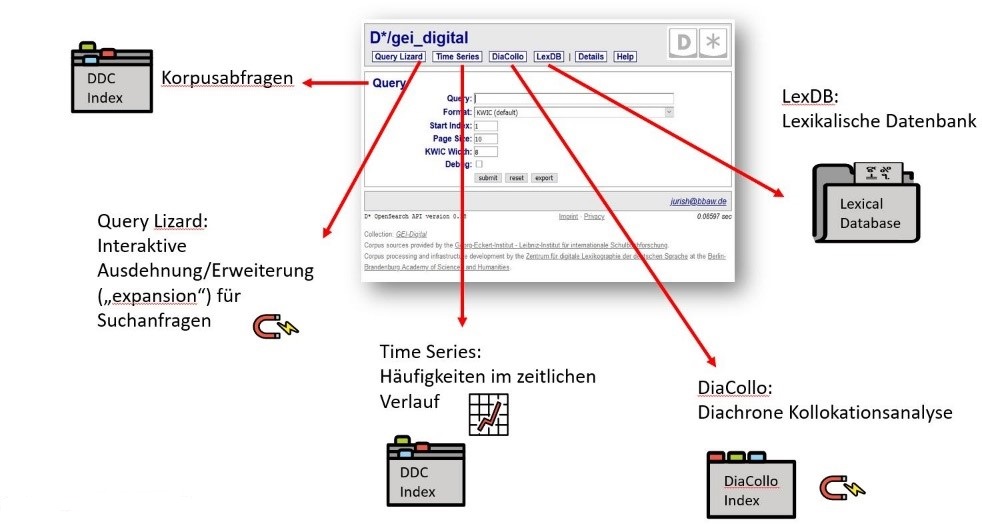
Abb. 1: Screenshot der D*-Korpusmanagement-Instanz des GEI mit dem Query-Werkzeug als Startansicht und Links zu weiteren verfügbaren Werkzeugen; Clipart von https://openmoji.org/, CC BY-SA 4.0
Abb. 1 zeigt die Startansicht der Benutzungsoberfläche in der Korpusmanagement-Umgebung D*, mit ausgewähltem „gei_digital“ (=GEI-Digital-2020) Korpus und standardmäßig zuerst angezeigtem Werkzeug „Query“ für Suchanfragen. Die auf dieser Seite angezeigten, bzw. verlinkten Werkzeuge greifen auf verschiedene, ihren Funktionen angepasste Indices zu. Sie können im Wesentlichen Zeichenfolgen finden, zählen, filtern und vergleichen. Manche Anfragen, bzw. deren Ergebnismengen, können von einem Werkzeug zum anderen „weitergereicht“ werden. Andere Anfragen können von unterschiedlichen Werkzeugen – auf etwas unterschiedliche Weise – bearbeitet werden.
Die Treffermengen von Suchanfragen (Queries) werden standardmäßig als „Stichwort im Kontext“ (KWIC-Format) angezeigt. Diese Ansicht ist üblicherweise mit den Digitalisaten der Quellen auf den Webseiten der jeweiligen Anbieter*innen – hier: GEI-Digital – verlinkt, so dass die Fundstellen dort einem Close Reading unterzogen und im breiteren Kontext der Quelle betrachtet und interpretiert werden können.
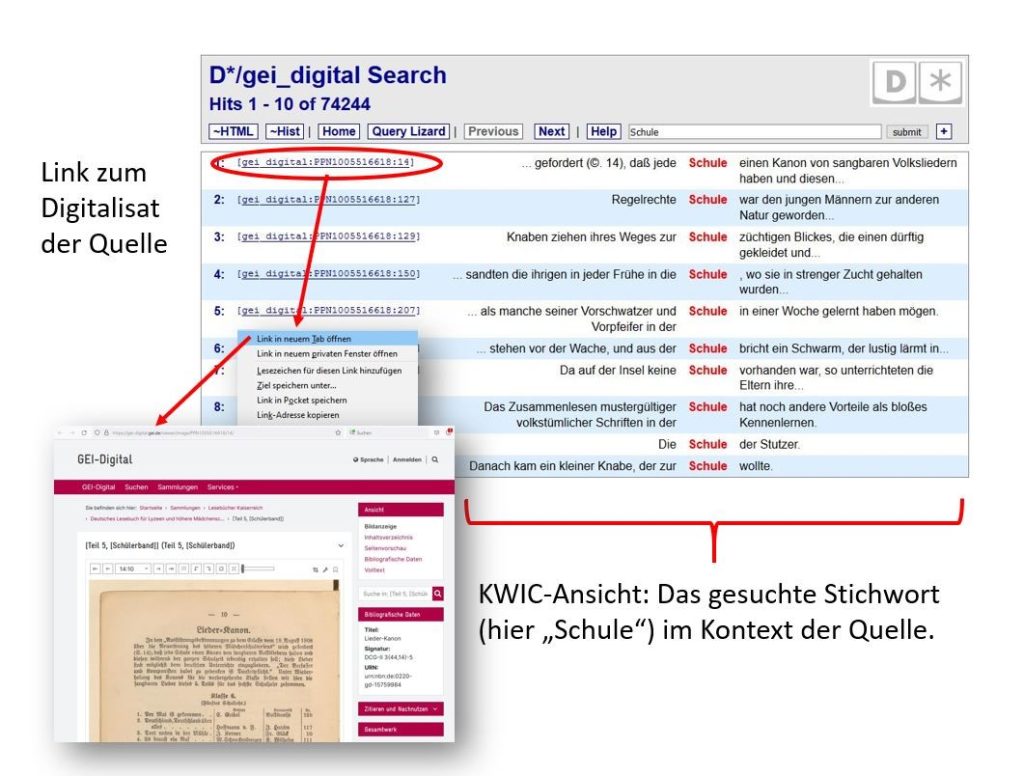
Abb. 2: Ergebnisansicht einer Suchanfrage im KWIC-Format, mit Links zu den Digitalisaten
Die derzeit verfügbaren Werkzeuge seien an dieser Stelle zunächst separat vorgestellt. Anschließend wird ihr kombinierter Einsatz anhand von Beispielen demonstriert.
- Ein wenig offensichtliches aber eminent wichtiges Werkzeug ist die Dokumentation von Korpus und Werkzeugen. Innerhalb von D* finden sich solche Informationen unter den Links „Help“ und „Details“. Sekundärliteratur und Angaben auf den Webseiten der Urheber*innen und Anbieter*innen ermöglichen idealerweise, Größe, Zusammensetzung und Datenqualität eines Korpus sowie die eingesetzten Algorithmen, und damit die Passfähigkeit zu eigenen Forschungsfragen abzuschätzen.
- Die Lexikalische Datenbank LexDB ermöglicht die Betrachtung des „Vokabulars“ eines Korpus, indem Rohdaten, aufbereitete Formen und Zusatzattribute mit ihren jeweiligen Frequenzen abgefragt werden können.
- Mit dem Time Series-Werkzeug kann die chronologische Verteilung einzelner gesuchter Stichwörter im Korpus visualisiert werden.
- Das Query Lizard-Werkzeug nutzt interne oder eingebundene Tools wie „GermaNet“[1], um zum Beispiel Synonyme, Ober- und Unterbegriffe zu eingegebenen Stichworten zu ermitteln. Die Ergebnisse können dann für entsprechend kombinierte Korpusabfragen direkt an das Query-Werkzeug weitergeleitet werden.
- Mit dem Query-Werkzeug wird der Hauptindex mittels einer Suchmaschine durchsucht. Die Suchmaschine verarbeitet sowohl einfache Stichworte als auch komplexe, kombinierte Abfragen und Filterungen, solange diese bestimmten Konventionen entsprechen.
- Das DiaCollo-Werkzeug ermittelt und visualisiert typische Wortverbindungen (Kollokate) zu einem gesuchten Stichwort und verwendet dazu einen eigenen Index. Die zu untersuchenden Zeitabschnitte können frei gewählt und verglichen werden. Einzelne Kollokationen können direkt als Queries für entsprechende Suchen im Hauptindex genutzt werden.[2]
Beispiele für die Nutzung der digitalen Werkzeuge: Recherchen zum Begriff der „Leistung“
Zunächst bietet es sich an, in der LexDB oder über entsprechende Zählungen und Frequenzverläufe das Vorhandensein und die Verteilung der zu untersuchenden Begriffe im Korpus zu prüfen. Unter den mehr als 544 Mio. individuellen Tokens des „GEI-Digital-2020“-Schulbuchkorpus finden sich zum Beispiel 49.289 Vorkommen[3] von Formen des Verbs „leisten“ (davon 19.426 als Infinitiv und 1.785 als finites Verb erkannt[4]) und 9.674 Treffer[5] für Formen des Substantivs „Leistung“ (2.720 Vorkommen im Singular[6] und 7.063 im Plural[7]). Hinzu kommen Wortverbindungen und andere Wortformen wie „Leistungsfähigkeit“ (1.548 Vorkommen[8]) und „leistungsfähig“ (249 Vorkommen[9]). Nicht mitzählbar sind hier diejenigen Zeichenfolgen, die von der automatischen Texterkennung nicht korrekt erfasst wurden. Sie können ggf. noch mit entsprechenden Suchen (wie z. B. nach Oberflächenformen, die mit der Zeichenfolge „Leist“ beginnen[10]) in der LexDB gefunden und für manuelle Auswertungen berücksichtigt werden.
Frequenzanalysen ermöglichen es, Verteilung und Häufigkeit eines Stichwortes zu vergleichen, z. B. über die Zeit, in bestimmten Teilmengen des Korpus (hier etwa Fächergruppen, Schulformen), zu Synonymen, Antonymen, verwandten Wortfeldern[11], oder auch zu anderen Spezial- oder Referenzkorpora[12], falls diese entsprechend aufbereitet zur Verfügung stehen. Eine Zählung der Vorkommen von „Leistung“ in den verschiedenen Untersammlungen[13] des „GEI-Digital-2020“-Korpus und der Vergleich mit der Anzahl der Token[14] in diesen Sammlungen gibt Anhaltspunkte dazu, in welchen Kontexten das Wort besonders oft eingesetzt wurde. Umgekehrt kann die Abwesenheit, wie hier etwa im Fall der Untersammlung „Fibeln“, darauf hindeuten, dass der Begriff z. B. nicht zum Register der Zielgruppe oder dem Vokabular der in den Texten beschriebenen Domänen gehörte.{[(|fnote_end|)]}
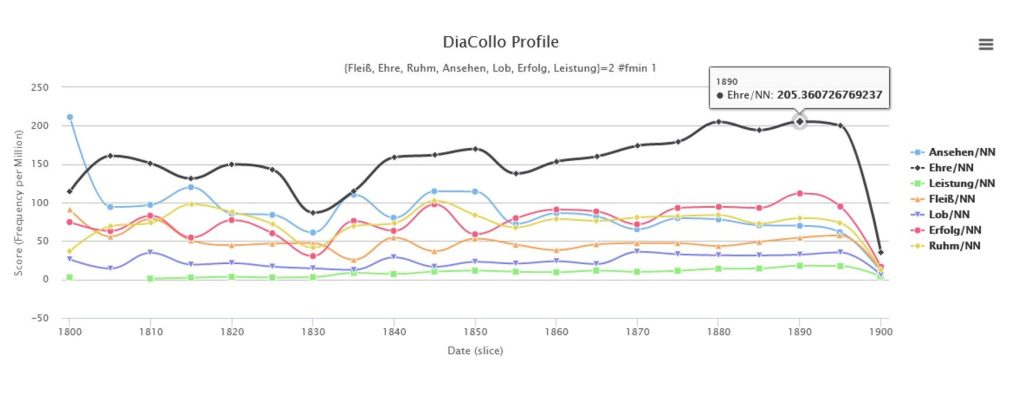
Abb. 3: Frequenzvergleich im Schulbuchkorpus (siehe Fußnote 11)
Die diachrone Kollokationsanalyse des Stichwortes „Leistung“[15] liefert Hinweise auf unterschiedliche Bedeutungsvarianten und mögliche Bedeutungswandel, indem in frei wählbaren Zeitabschnitten diejenigen Worte/Wortformen ermittelt werden, die statistisch auffällig häufig gemeinsam mit dem Stichwort vorkommen. Im Schulbuchkorpus sind dabei erst ab den 1830er Jahren genügend Daten für die Analyse mit dem DiaCollo-Werkzeug vorhanden. Diese frühen Kollokate deuten auf eine Verwendung in ähnlichem Sinne wie Dienst/Eid/Gehorsam leisten hin. Ab den 1850er und 1860er Jahren weisen die Kollokate zu „Leistung“ auf die Verwendung in neuen Domänen („literarisch“, „College“ und „Dampfwagen“, „Wissenschaftlich“, „Dichtkunst“). Und ab den 1900ern finden sich Kollokate, die einen Bezug zu Schule vermuten lassen, bzw. gemeinsame Kollokate der beiden Stichworte „Leistung“ und „Schule“[16] wie etwa „Unterricht“, „lateinisch“ oder „Lehrer“. Eine Reihe anpassbarer Parameter und Optionen von DiaCollo ermöglicht dabei, sich bestimmten Aspekten anzunähern, z. B. nur nach Adjektiv-Kollokaten[17] zu suchen.
Vergleiche mit anderen Korpora sind indirekt möglich, wenn diese ebenfalls entsprechend indexiert wurden und über eine DiaCollo-Instanz abgefragt werden können. Auch im Kern-Referenzkorpus des „Deutschen Textarchivs“ (DTA) deuten die stärksten Kollokate zum Stichwort „Leistung“[18] auf unterschiedliche Verwendungen und Bedeutungen hin (1630er: „Untertänigkeit“, „Eid“, „Gehorsam“, „verpflichten“; 1910er: „Anerkennung“, „Beförderung“, „Ehrendiplom“, „verleihen“). Im Polytechnischen Journal, das sich mit den neuesten naturwissenschaftlichen und technischen Entwicklungen beschäftigte, deuten die Kollokate[19] auf eine domänenspezifische Verwendung (1910er: „PS“, „KW“, „effektiv“, „Turbine“, „Wirkungsgrad“).
Einfache und komplexe Suchen ermitteln oder zählen konkrete Belegstellen. Hier drei Beispiele, bei denen Suchen kombiniert oder auf Wortarten eingeschränkt, die Suche durch entsprechend formulierte Filter auf bestimmte Werkgruppen eingegrenzt, und die Ergebnisse sortiert werden:
- Die Abfrage „$p=ADJA Leistung“ #HAS[geiclass,’Geschichtsschulbuecher vor 1871′] findet im Schulbuchkorpus 216 Vorkommen eines Adjektivs direkt vor einem Vorkommen des Lemmas „Leistung“ (also „außerordentliche Leistungen“, „bestimmte Leistung“, „schwächere Leistungen“ usw.) in allen Werken, die per Metadatum der lokalen Klassifikation „Geschichtsschulbücher vor 1871“ zugerechnet sind.[20]
- COUNT(NEAR(Leistung, Mädchen, 20)) #BY[date/10] listet die Anzahl der Treffer für Formen von „Leistung“ und „Mädchen“, die im Abstand von maximal 20 Token innerhalb desselben Satzes vorkommen, nach Dekade gruppiert[21]. Die insgesamt 54 Treffer werden mit folgender Suchanfrage als Stichwort im Kontext (KWIC) angezeigt: NEAR(Leistung, Mädchen, 20).[22] Für eine Suche bezogen auf gemeinsames Vorkommen in Absätzen formuliert man Leistung && Mädchen #within p.
- Die Abfrage „Leistung #HAS[bibl,/Lehrer/] #asc_date“ findet 379 mal die Zeichenfolge „Leistung“ in Werken, in deren Titel (also dem Metadatenfeld für diese bibliografische Angabe) die Zeichenfolge „Lehrer“ vorkommt und listet die Ergebnisse aufsteigend nach Publikationsdatum. So werden Treffer in Werken zusammengefasst, deren Titel z. B. „Lehrerhandbuch“ oder „Handbuch für Lehrer“ lautet oder in denen ein Begriff wie „Lehrerbildungsanstalten“ vorkommt.[23]
Die kombinierte Verwendung dieser Werkzeuge ermöglicht somit die explorative Annäherung an digitale Textsammlungen und unterstützt die Bildung von Hypothesen durch die Bereitstellung statistischer Auswertungen und konkreter Belegstellen. Ein Wechsel zwischen, bzw. die kombinierte Nutzung von Distant Reading und Close Reading der einzelnen Texte im Digitalisat der Quelle ist jederzeit möglich. Dies ist auch notwendig, denn die hier eingesetzten Algorithmen können den Sinn der gefundenen Zeichenketten nicht erfassen. Für eine (teil-)automatische Klassifizierung, Gruppierung oder Annotation bestimmter Phänomene in den Daten wäre der Einsatz künstlicher Intelligenz wie machine learning vonnöten, die diese regelbasiert, eigenständig lernend oder an Trainingsdaten orientiert durchgeführt würde. Bis auf weiteres bleibt die Auswertung der Treffermengen aber interpretative Aufgabe der Nutzer*innen; es gilt Wittgensteins Diktum: „Nur der Satz hat Sinn; nur im Zusammenhange des Satzes hat ein Name Bedeutung.“[24]
Der „Schul-Sprachschatz“ des „GEI-Digital-2020“ Korpus ist über die Projektwebseite (https://diacollo.gei.de/), aber auch als Bestandteil der „Historischen Korpora“ des Digitalen Wörterbuchs der deutschen Sprache (DWDS) frei nachnutzbar.[25]
Anmerkungen
Literatur