Im Verlauf des 19. Jahrhunderts etabliert sich die Vermittlung von Literatur im deutschsprachigen Unterricht an höheren Schulen. Seitdem gehört Literatur zum integralen Bestandteil des Fachs Deutsch an weiterführenden Schulen und zu ihren kanonischen Unterrichtsgegenständen.
Den Diskurs dieser Entwicklung untersucht das Projekt „‚Lesen heißt diese Übung‘ – und dann? Begriffe und intendierte Praktiken der Vermittlung deutschsprachiger Literatur an höheren Schulen 1796–1890“ (, doi:10.25625/APN9VH) mit einem Schwerpunkt auf Preußen vor dem Hintergrund zweier Leitfragen: Inwiefern wird die Fachlichkeit der schulischen Literaturvermittlung durch das Verhältnis zwischen der Entwicklung von Ausdrücken zu Begriffen mit terminologischer Qualität, intendierten Unterrichtspraktiken und Vermittlungszielen formiert? In welchen Bezügen steht diese Fachlichkeit zur Änderung des kollektiven Begriffsinventars von vormodernen zu modernen Semantiken innerhalb der sogenannten Sattelzeit (1750–1850) ?
Operationalisiert werden diese Fragestellungen anhand des scalable Reading von Quellen, die im Vorfeld zu einem maschinenlesbaren Korpus aggregiert wurden: Fachlichkeit des Deutschunterrichts: Literaturvermittlung, FaDe:Live (1782–1891). Zum Zeitpunkt der Finalisierung des Korpus im April 2025 enthält es alle digitalisierten Monographien, Zeitschriftenartikel und staatlichen Lehrpläne zur Literaturvermittlung im Rahmen des Untersuchungsfokus. Es setzt sich aus klassischen ideengeschichtlichen Quellen der Bildungsgeschichte wie etwa Auszüge aus Basedows Elementarwerk (1785), aus der von Joachim H. Campe herausgegebenen Revision (1787) und aus Friedrich D. E. Schleiermachers Erziehungslehre (1813) sowie zu einem Großteil aus bisher nicht beachteten Quellen zusammen. In der aktuellen Version ist es ein adäquates Modell des öffentlich-schriftlichen Diskurses über Literaturvermittlung an höheren Schulen im 19. Jahrhundert. Damit bietet das Korpus eine Quellengrundlage für eine integrative und interdisziplinäre Geschichte der Fachlichkeitsforschung (vgl. ).
Quellen und Autoren
Die Quellen stammen aus heterogenen Archiven. Neben der Verwendung der vielen digitalen Angebote im deutschsprachigen Raum zu bildungsgeschichtlichen Quellen – von denen sich die größten Sammlungen auf GEI-Digital des Georg-Eckert-Institut in Braunschweig, auf ScriptaPaedagogica der Bibliothek für Bildungsgeschichtliche Forschung in Berlin und in der Digitalen Bibliothek des Münchener DigitalisierungsZentrum befinden – mussten einige relevante Texte zunächst in weiteren Bibliotheken wie der Staatsbibliothek zu Berlin identifiziert und gescannt werden. Neben Funden in kleineren digitalen Archiven zählen ebenso Digitalisate aus den Sammlungen von Google und dem Internet Archive zum Korpus. Sowohl für die Zusammenstellung digitaler als auch analoger Quellen aus Zeitschriften wurde eine Liste erstellt, die mit 119 Zeitschriften mindestens einen Großteil aller im 19. Jahrhundert erschienenen pädagogischen Zeitschriften zu höheren Schulen in Deutschland umfasst. In den entsprechenden digitalen Repositorien und analogen Exemplaren der Zeitschriften wurden deren Inhaltsverzeichnisse und Artikeltitel durchgesehen, um relevante Aufsätze und Rezensionen zu filtern. Aus den Digitalisaten wurden manuell die Texte extrahiert, die im Kontext der Fragestellung und des Untersuchungszeitraums relevant sind. Die analogen Quellen wurden fotomechanisch gescannt und in PDF-Dokumente konvertiert. Dafür umfasste das Magazin der BBF eine hervorragende Sammlung gedruckter Quellen, in der während eines Forschungsaufenthalts im Winter von 2022 auf 2023 weitläufig recherchiert wurde.
Aus den 1022 recherchierten Texten konnten letztlich 963 in guter Qualität OCR verarbeitet werden.
| Textklasse | Texte | Tokens |
|---|---|---|
| Zeitschriftenartikel | 893 | 3.239.051 |
| Lexikonartikel | 21 | 226.241 |
| Monographie | 32 | 1.778.254 |
| Verordnung | 15 | 48.910 |
| Rede | 2 | 4.693 |
| Summe | 963 | 5.297.149 |
Tabelle 1: Übersicht über die Quellen
Viele Monographien zum deutschsprachigen Unterricht im 19. Jahrhundert sind bereits digitalisiert. Darunter befinden sich alle bisher in der Historiographie des Deutschunterrichts rezipierten Monographien. Ebenfalls wurden alle pädagogischen Lexika, die im Kontext der Fragestellung relevant sein könnten, auf Artikel durchsucht. Dabei hat sich herausgestellt, dass nur die Encyklopädie des gesammten Erziehungs- und Unterrichtswesens (1859ff.) viele wichtige Artikel enthält. Weitere Nachrecherchen ergaben zudem, dass diese bildungshistorisch bedeutsame und umfangreichste Enzyklopädie des 19. Jahrhunderts bisher nicht Gegenstand bildungshistorischer Forschung war . Das Korpus umfasst darüber hinaus die zwei für die zeitliche Eingrenzung wesentlichen Reden von Johann G. Herder (1796) und Friedrich Wilhelm II (1890) sowie nicht digital verfügbare Aufsätze aus analogen Anthologien. In den bisher angeführten Textklassen wird gleichzeitig eine Limitation des Projektes deutlich: Schulprogramme und die Verordnungen anderer deutscher Staaten als Preußen wurden nicht in das Korpus integriert. Das hat den pragmatischen Grund der zeitlichen sowie personellen Limitierung des nur von einem Forscher durchgeführten Projektes im Rahmen der wissenschaftlichen Qualifikationsphase. Parallel zur Zusammenstellung des Korpus wurden die Texte mit Metadaten in einer CSV-Datei erfasst.
So versammeln sich in dem Korpus die schon angeführten Texte der prominenten Theoretiker und Praktiker genauso wie solche, die bisher paradigmatisch für die Entwicklung des Deutschunterrichts stehen, wie Otto Lyon, Ernst Laas, Rudolf Lehmann, Rudolf Hildebrandt, Robert H. Hiecke und K. E. Philipp Wackernagel. Aber auch weniger bekannte Autoren wie Heinrich Viehoff und Heinrich Deinhardt und schließlich bisher kaum rezipierte aber produktive Schulmänner wie Karl Gude finden sich unter den Verfassern. Der wirklich spannende Teil an dieser Partie ist einerseits die diskursive Verflechtung von Pädagogik und nationalsprachlicher Fachlichkeit sowie damit von Ästhetik, Philosophie, Politik und Religion. Andererseits umfasst das Korpus ganz im Sinne der Literaturwissenschaftlerin Margaret Cohens mit den 421 namentlich genannten und 88 ungenannten Autoren einen wesentlichen Teil der „great unread“ der Literaturvermittlung an deutschen höheren Schulen im 19. Jahrhundert .
Aufbereitung
Etliche der quellenkritisch erschlossenen Digitalisate weisen eine unzureichende OCR-Qualität auf, was das Natural-Language-Processing, die Visualisierungen sowie die aus den Daten abgeleiteten Ergebnisse verzerrt . Um die Qualität der maschinenlesbaren Texte zu erhöhen und weil die meisten in Fraktur gesetzt sind, wurde OCR4all verwendet – das open source Tool, mit der besten OCR-Qualität für historische Texte von Christian Reul et al. . In einem Vergleich mit dem kostenpflichtigen Abbyy-Finereader und Googles open-source Bibliothek tesseract hat OCR4all die besten Ergebnisse erzielt. Auch das kostenpflichtige Programm Transkribus kann die PDF-Dokumente, die OCR4all Schwierigkeiten bereiten, nicht in einer zufriedenstellenden Qualität scannen. Ein Nachteil von OCR4all ergab sich aus der Tatsache, dass zum Zeitpunkt der Erstellung des Korpus nur einzelne Texte OCR gescannt werden konnten, was sich als äußerst zeitintensiv gestaltete.
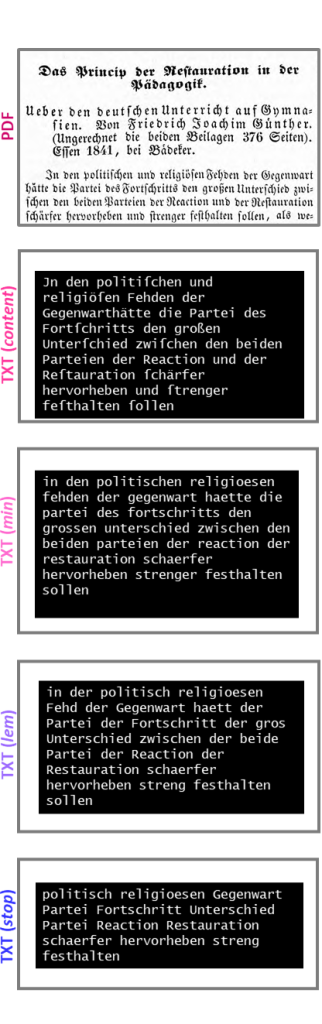
Abb. 1: OCR und NLP am Beispiel von Robert Heinrich Hieckes: Das Princip der Restauration in der Pädagogik (1841)
Nach dem OCR liegt jede Quelle als einzelne, mit einer ID versehenen Textdatei vor. Diese IDs sind essenziell für die Nachnutzung, die weitere Verarbeitung, das Mapping der Metadaten und die Transposition in XML bzw. TEI zur Archivierung. In einem ersten Verarbeitungsschritt von den maschinenlesbaren TXT-Dateien (raw) wurden Kopf- und Fußzeilen, Titel, Inhaltsverzeichnisse etc., d.h. alle paratextuellen Elemente getilgt. Erst TXT (content) entspricht dem Textkorpus der Untersuchung. Diese so bearbeiteten Texte werden in die CSV-Datenbank integriert, um eine kombinierte Datei aus Metadaten und Text zu erzeugen. Zur Erleichterung der späteren Arbeit mit den Daten, wie etwa die Bildung von Subkorpora und die Erzeugung von Statistiken, wurde MongoDB als eine der niedrigschwelligeren Datenbanken genutzt. Zwar hat Mongo eine Benutzeroberfläche, jedoch auch eine eigene Abfragesyntax, sodass für Projekte dieser Art, solange kein:e entsprechenden Spezialist:innen Teil des Teams sind, für eine erste Korpuserstellung eine CSV-Datenbank empfehlenswert ist. Für alle bisher dargestellten Prozesse und auch für alle weiteren Verarbeitungen der Daten wurde die Programmiersprache Python verwendet.
Nüchtern gesprochen ermöglicht Python einen einfachen Zugriff auf CSV-Dateien sowie Datenbanken und eignet sich sehr gut zur Verarbeitung von Text in Form von Matrizen und Listen sowie mit kuratierten Programmbibliotheken für einfaches (nltk, spaCy) und komplexes Natural-Language-Processing (scikit-learn, gensim, mallet). Mit der Emphase eines Philologen ausgedrückt: Es ist ein einzigartiges Alchemielabor.
Die erste Verarbeitungsstufe ist TXT (min): Trotz OCR entstehen Fehler und abweichende Schreibweisen, sodass alle Ausdrücke mit vier oder weniger Nonsens-Buchstabenfolgen getilgt und Ausdrücke normalisiert wurden. Dadurch konnte die OCR-Qualität von einer Fehlerquote von 8,9 Prozent auf 3,7 Prozent reduziert werden, was für eine Erzeugung von Word-Vektor-Modellen sehr gut bis ideal ist – siehe hierzu weiter unten.
Mit einer Ersetzungsfunktion werden in der Verarbeitungsstufe TXT (min) außerdem Zeilenumbrüche, Absätze und Bindestriche getilgt, um getrennte Wörter an Zeilenenden als ganze Wörter zu rekonstruieren. Außerdem werden in dieser Vorverarbeitungsstufe alle Buchstaben in Minuskel gesetzt, da großgeschriebene Satzanfänge unterschiedlichster Wortarten zu einer unscharfen Lemmatisierung führen.
Die Lemmatisierung mit dem HanoverTagger reduziert Wörter auf ihre morphologischen Grundformen, was angesichts der unterschiedlichen sowie historischen Schreibweisen als herausfordernd und fehleranfällig ist. Diese Vorverarbeitungsstufe wird hier als TXT (lem) bezeichnet. Darüber hinaus werden alle Sonderzeichen getilgt, um Themen modellieren und Texte anhand von Clusteranalysen vergleichen zu können. Die Entfernung von Stoppwörtern ist erst nach einer Lemmatisierung von TXT (min) zu TXT (lem) sinnvoll, weil dann auch alle Variationen von Deklinationen und Konjugationen berücksichtigt werden. Stoppwörter, die keine semantische Relevanz besitzen, werden entfernt – mit Ausnahme von Wörtern, die im Kern Negation oder Totalität semantisieren wie „nicht“ oder „ganz“. Negationen sind für die Verfächerung, Fachlichkeit und die damit einhergehende Wissensproduktion selbst konstitutiv, da sie zwischen fachlich Angemessenem und fachlich nicht Angemessenem unterscheiden, damit Einschluss, Ausschluss und Kontinuität erzeugen . Ausdrücke, die hingegen auf Totalität abzielen, sind einerseits für den im 19. Jahrhundert entstehenden Nationalismus zur Konstruktion kulturell homogener Staaten und andererseits für die fachliche Ausdifferenzierung vor dem Hintergrund idealistischer Philosophie grundlegend. Die beiden Annahmen bestätigt das Korpus: „nicht“, „deutsch“, ganz“, „wort“, „schueler“ sind die fünf häufigsten Ausdrücke.
Den gesamten Workflow zur Erstellung des Korpus und dessen Vorverarbeitung skizziert das folgende Flussdiagramm:
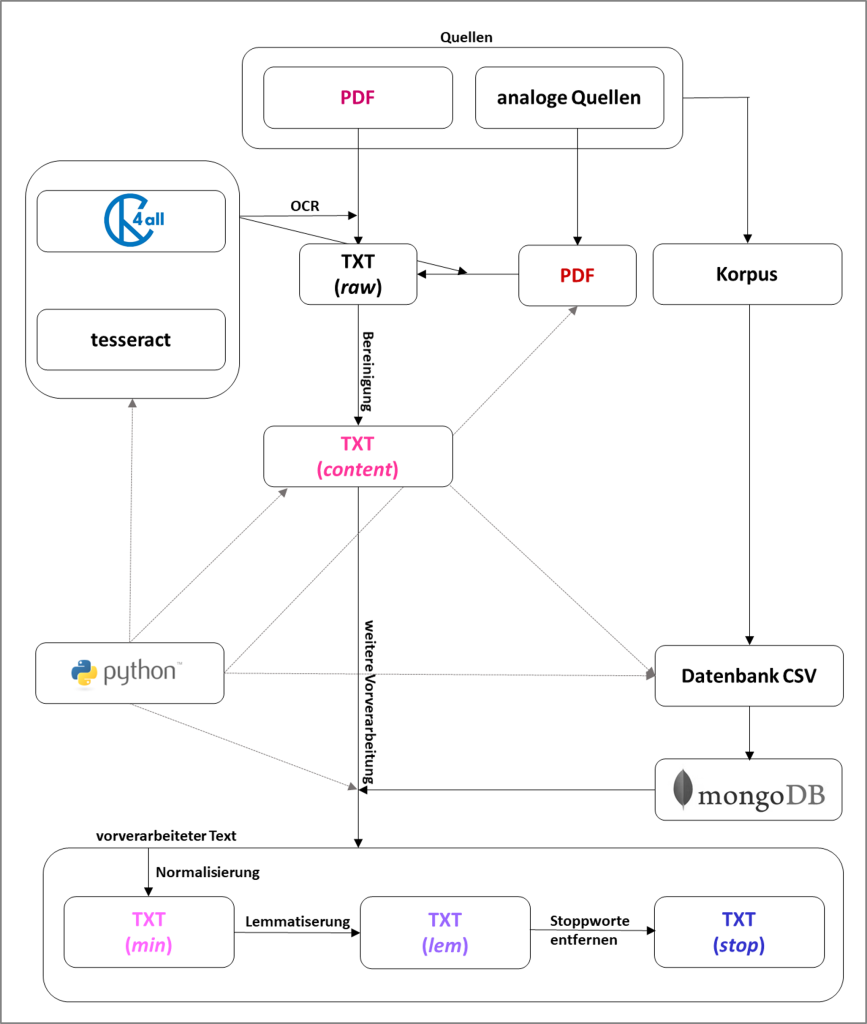
Abb. 2: Ein Verfahren zur Erstellung digitaler Korpora; eigene Darstellung
Perspektiven auf das skalierbare Lesen maschinenlesbarer Korpora
Die datafizierten Artefakte ermöglichen eine Analyse des Korpus, für die Franco Moretti den Asudruck distant Reading geprägt hat und der seitdem als ein heuristischer Terminus für quantitative Korpusanalysen in den Digital Humanities verwendet wird. Analog zum distant Reading und close Reading wird mit der Metapher scalable Reading (skalierbares Lesen) ein stufenweiser Wechsel zwischen unterschiedlich nahen und distanzierten analytischen Dimensionen heuristisch umschrieben (vgl. ). Die damit verbundenen Verfahren sind teilweise methodisch aufeinander angewiesen und ermöglichen in ihrer Kombinatorik differenzierte Einblicke in das Korpus, die im Folgenden anhand zweier Beispiele als Ausblick auf analytische Optionen grob skizziert werden.
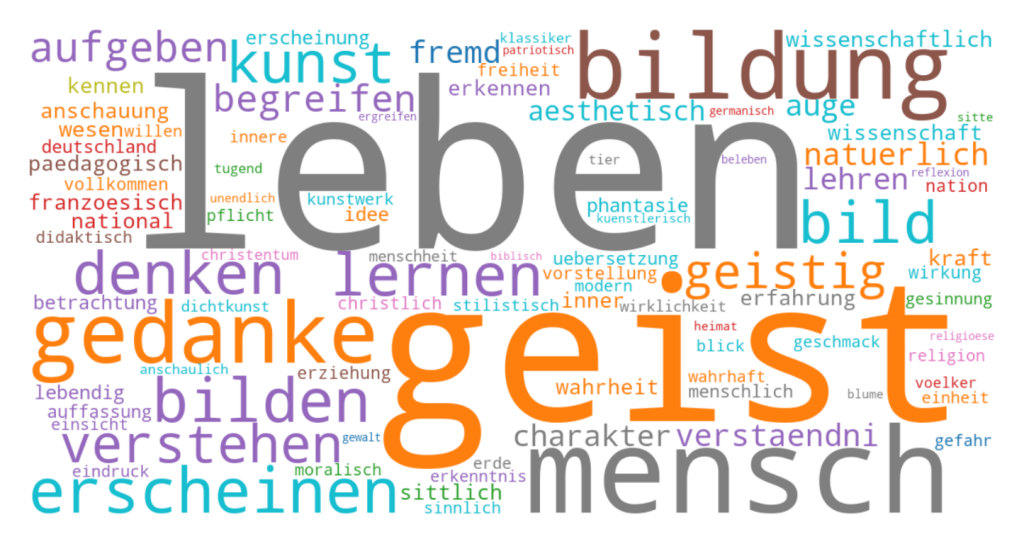
Abb. 3: Wortwolke des extrahierten Termkandidatenvokabulars Begriffe 2.2 zur Veranschaulichung der Analyse des interdiskursiven Vokabulars von FaDe:Live, basierend auf tf-idf-Werten (, Begriffe_8_Termset_2.2_wordcloud_tfidf.png)
Wortwolken gehören mittlerweile zu standardisierten und automatisierten Komprimierungen des lexikalischen Materials auf Webseiten. Hier veranschaulicht die Grafik das Ergebnis einer reduktiven Analyse des Vokabulars des Korpus mit Clusterverfahren und Word-Embeddings in Hinblick auf interdiskursive und konzeptionelle Ausdrücke. Weil sie in dieser Hinsicht für den Diskurs konstitutiv und terminologisch relevant sind, bilden sie ein Termkandidatenset, oder einfacher ausgedrückt: ein Termset. In der Grafik entspricht die Größe der Ausdrücke ihrer Relevanz anhand der term frequency-inverse document frequency-Werte (tf-idf – ein Wert, der die absolute Frequenz eines Ausdrucks in einem Text in Hinblick auf das Vorkommen dieses Ausdrucks in allen anderen Texten des Korpus relativiert). Die Farben sind nur Indizes zur Unterscheidung der manuell interpretierten Kategorien der knapp 1000 relevantesten Ausdrücke und tragen keinen semantischen Wert: Alterität (blau, bspw. „fremd“), Moral (grün, bspw. „sittlich“), Anthropologie (grau, bspw. „leben“), Idealismus (orange, bspw. „geist“), Ästhetik (türkis, bspw, „bild“), Pädagogik (braun, bspw. „erziehung“), Praktik (lila, bspw. „lernen“), Nation (rot, bspw. „franzoesisch“). Aus dem interdiskursiven Vokabular der Literaturvermittlung könnten nun einzelne Ausdrücke oder spezifische Kombinationen von Ausdrücken weiter analysiert werden: etwa diachron anhand von Wortverlaufskurven über das gesamte Korpus hinweg, synchron anhand der Verteilungssemantik in einem Wort-Vektor-Modell oder im close Reading anhand konkreter Texte sowie Textstellen.
Der rosa Elefant schwebt über der Wolke: Der national getaggte Ausdruck „deutsch“ befindet sich in allen relevanten Vokabularen des Korpus an erster Stelle. Der Diskurs der Literaturvermittlung an höheren Schulen ist in Preußen im 19. Jahrhundert, was nicht weiter verwundert, im Kern nationalkulturell geprägt – das gilt für die Literaturvermittlung an weiterführenden Schulen in den DACH-Staaten bis heute. Die sich daran anschließende Frage zielt auf das fachliche Selbstverständnis des Deutschunterrichts und der schulischen Literaturvermittlung ab: Müssten nicht innerhalb des Faches terminologische Kontinuitäten reflektiert und diese angesichts eines deutlich veränderten gesellschaftlichen und politischen Systems, das nicht mehr nationalstaatlich ist, entsprechend gekappt werden?
In der folgenden Grafik verschmelzen die Analyse der Texte, der algorithmisch (re-)konstruierten Topics und des interdiskursiven Vokabulars in einem Verlaufs- und Balkendiagramm.
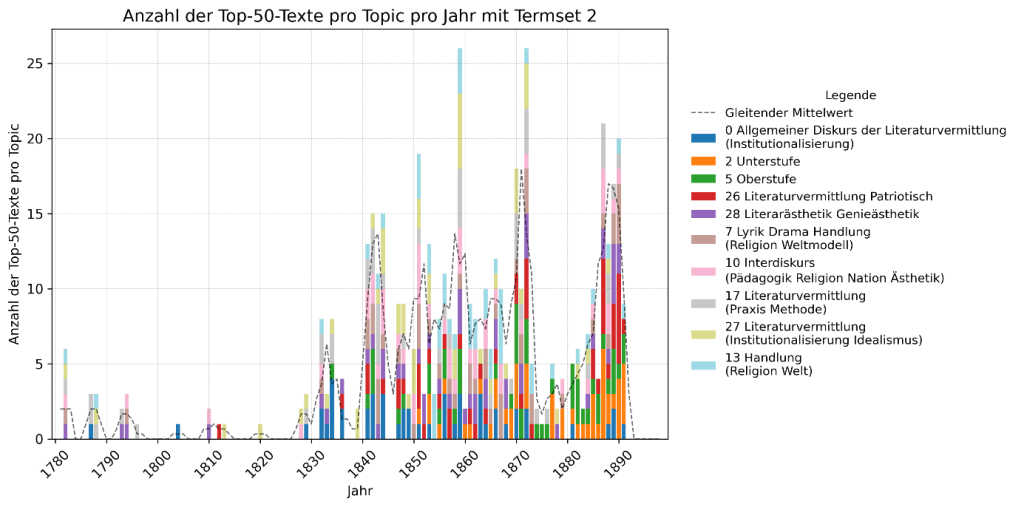
Abb. 4: Top-50 Texte der Top-10 Topics relativiert auf Termset Begriffe 2 verteilt auf Jahre als ein Ergebnis der Analyse des interdiskursiven Vokabulars von FaDe:Live (: Begriffe_7_Termset_2_Topics_pro_Jahr_diff.png)
Mit dem in die Pipeline von Bayerschmidt ingegrierten Topic-Model-Algorithmus MALLET wurden 30 Topics ermittelt. Abbildung 3 zeigt die 50 wichtigsten Texte der zehn wichtigsten dieser 30 Topics relativ zum Termkandidatenset im Zeitverlauf.
Jeder Datenbalken repräsentiert den Anteil der 50 Texte, die in einem der Jahre des Korpusintervalls veröffentlicht wurden und einem auf das Termset relativierte Topic am ehesten entsprechen. So sind etwa im Jahr 1782 auf sechs verschiedene Topics jeweils ein Text verteilt. Im Jahr 1891 sind auf fünf verschiedene Topics neun Texte verteilt, darunter die meisten auf das Topic 2 Unterstufe. Die gestrichelte Linie modelliert die Entwicklung der interdiskursiven Terminologie des Fachdiskurses anhand des gleitenden Mittelwerts der summierten Anzahl der Top-Texte pro Topic und Jahr. Damit ist das Diagramm eine mögliche Visualisierung der Entwicklung der interdiskursiv geprägten Terminologie des literaturvermittelnden Diskurses. Daraus lassen sich etwa ableiten:
- die diskursiv relevanten Intervalle, wie zum Beispiel 1841 bis 1844,
- die Entwicklung thematischer Schwerpunkte innerhalb des Diskurses, wie zum Beispiel der Relevanzverlust einer idealistisch geprägten und mit der Institutionalisierung der Literaturvermittlung verbundenen Semantik (Topic 0 und 27) ab den 1870er Jahren sowie in den 1880er Jahren eine stärkere Fokussierung des Diskurses auf Aspekte der Unterstufe und auf eine patriotisch ausgerichtete Literaturvermittlung (Topic 2 und 26).
Schluss
Das dargestellte Projekt ist von der Aggregation des Korpus über die Aneignung der Methoden bis hin zu Auswertung sehr aufwendig. Ohne die Digitalisierung in nach Qualitätsstandards arbeitenden Forschungs- und Universitätsbibliotheken ist diese Arbeit kaum möglich. Erschwert wird sie durch die prekäre Situation vieler Wissenschaftler:innen in der akademischen Qualifikationsphase. Darüber hinaus sind die humanwissenschaftlichen Disziplinen in Hinblick auf die beschriebenen Ansätze noch weitestgehend unsortiert. Um einen fruchtbaren Nährborden für die Entstehung und Entwicklung solcher Arbeiten zu bereiten, müsste die Gemeinschaft dieser Disziplinen sowohl innerhalb als auch übergreifend methodischen Innovationen gegenüber offener sein und neue beziehungsweise andere Perspektiven auf Tradiertes zulassen. Idealerweise werden solche Projekte begleitet von einem interdisziplinären Rahmenprogramm, etwa im Kontext von thematisch ausgerichteten Arbeitsgruppen oder Kollegs, oder werden von Lehrstühlen geleitet, deren Forschungsumgebung die Aneignung der methodischen Grundlagen für Qualifikand:innen ermöglicht, wie etwa durch Zertifikatskurse für die Digital Humanities und Sozialwissenschaften.
Zu den fördernden Rahmenbedingungen möchte auch die hier skizzierte Arbeit beitragen, indem das methodische Vorgehen und die Daten zur Evaluation, Nachnutzung und Anknüpfung Interessierten frei zugänglich gemacht wird. Erste Versionen des Datasets von FaDe:Live wurden im Repositorium GRO.data abgelegt (, doi:10.25625/APN9VH). GRO.data ist Teil der eResearch Alliance der Gesellschaft für wissenschaftliche Datenverarbeitung, die von der Max Planck Gesellschaft sowie der Georg-August-Universität Göttingen gegründet wurde. Ein ganz wesentlicher Vorzug von GRO.data ist der unmittelbare Zugang für Mitarbeitende an niedersächsischen Universitäten über die digitale Infrastruktur Academic Cloud. Dass der Ablage-Service nur Mitarbeitenden niedersächsischer Universitäten zur Verfügung steht, ist gleichzeitig ein Nachteil dieses Repositoriums. Das Dataset umfasst als Ergänzung bisher zwei Poster (, doi: 10.48693/730), welche die Aufbereitung des Korpus und die Verarbeitung der Daten skizzieren, die Metadatendatei und erste Ausgaben des verarbeiteten Korpus, Statistiken, Grafiken und das Vokabular der Verarbeitung TXT (stop). Das Dataset wird kontinuierlich erweitert, sodass es mit der Finalisierung den FAIR-Prinzipien entspricht: Alle Texte werden in der Verarbeitungsstufe content als TXT und als XML (TEI) mit IDs sowie Links zu den Digitalisaten, die verschiedenen Statistiken in Form von Listen sowie Matrizen, Grafiken, der Code und Metadaten der wissenschaftlichen Gemeinschaft zur Verfügung gestellt. Die zur Verarbeitung, Reproduktion und Exploration des Korpus verwendete Software findet sich vollständig auf GitHub (, https://github.com/hendheim/FaDeLive). Der Abschluss des Projektes ist 2026 geplant.
Das heißt nicht, dass damit beansprucht wird, die Geschichte der Fachlichkeit des Deutschunterrichts im 19. Jahrhundert abzuschließen – im Gegenteil. Zum einen bieten die digitalen Geistes- und Sozialwissenschaften neue Perspektiven auf die schon bestehenden Historiographien, die bestehende Forschung bestätigen und weiter herausfordern wird. Zum anderen sind im Kontext einer digitalen Bildungsgeschichte Daten aggregierende Projekte anschlussfähig, in der das bisherige Korpus um Schulprogramme , Abituraufsätze , Verordnungen, Quellen süddeutscher Gebiete und auch um solche der DACH-Staaten sowie Luxemburg und der deutschsprachigen Gemeinschaft in Belgien erweitert werden kann. In einem sehr weiten zeitlichen und geographischen Winkel ist eine kultur- und disziplinübergreifende Geschichte der Fachlichkeiten möglich, weil es eine gemeinsame Basis gibt: maschinenlesbare Texte.